


OCR (Optical Character Recognition) is a solution that transforms an image into machine-readable and editable text, easing the data extraction process.
It is an underlying software for Intelligent document processing. However, the OCR alone is not smart enough to understand the context and process the document with 100% accuracy.
Optical Character Recognition(OCR) technology works simply by identifying the difference between background and text through pixels. However, with some best practices, we can improve the OCR accuracy to ensure that each data extracted using OCR is accurate.
Here, we will learn how to improve OCR accuracy, but before that, let’s briefly describe OCR accuracy, how it works, and how to calculate OCR accuracy.
What is OCR Accuracy?
OCR accuracy determines how well the OCR software can transform printed or handwritten text from scanned images into digital format. It refers to the rate of accuracy in the produced machine text compared with the letters, numbers, symbols, and words in an original document.

For instance, when you scan a printed book into a digital text document, OCR accuracy assesses how faithfully the software captures each character and word from the scanned pages. It ensures the resulting digital text closely mirrors the original content’s layout and content.
To ensure high accuracy in OCR tests, it’s important to understand the OCR workflow.

How to Calculate OCR Accuracy?
Measuring or Calculating OCR accuracy involves comparing an OCR system’s output to the source text and determining the accuracy of the transcribed content.
Here’s step-by-step guide to calculate OCR accuracy:
Step 1: Obtain Ground Truth Data
You need the source text (ground truth) document as the reference for accuracy assessment.
Example: If you’re doing OCR to a printed book, obtain a digital version of the book as the ground truth, which contains the accurate text of the entire book.
Step #2: Perform OCR
Run the OCR software or engine on the source images or documents to convert them into digital text.
Example: Use OCR software to scan each printed book page and convert it into digital text. Save the OCR-generated text as a separate file.
Step #3: Text Comparison
Compare the OCR-generated text with the ground truth text character by character or word by word.
Example: Compare a specific page from the OCR output to the corresponding page in the ground truth. Identify differences, such as incorrect characters or words.
Step #4: Count Errors & Calculate Accuracy
Identify and count the errors, which can include substitutions (incorrect characters or words), insertions (extra characters or words), and deletions (missing characters or words).
There are two matrices based on the concepts of Levenshtein to measure the OCR accuracy: character error rate and word error rate.
Character Error Rate (CER) Formula to Calculate OCR Accuracy
Here’s how you can calculate document accuracy with Character Error Rate(CER) method. Check the Character Error Method(CER) formala below:

For instance, if the number of characters is 1000, and the total required correction (I+S+D) is 50.
Then, the CER will be 5%, which means OCR accuracy is 95%.
Look at the example below to understand how to calculate insertions (i), substitutions (s), and deletions(d) of characters required to obtain the ground truth result.
Growth Truth Text: S8999483
OCR output text: 89g9h83M
- S is missing = Insertion [I = 1]
- G & h instead of 9 and 4 respectively = Substitution [S = 2]
- M is addition = Deletion [D = 1]
Total number of characters in growth truth text: 8 [N = 8]
CER = [ (I + S + D) / N ]*100%
CER = 4/8*100 = 50%
Word Error Rate (WER) Formula to Calculate OCR Accuracy
Word error rate looks after the incorrect words. Here’s the formula below to calculate OCR accuracy using Word Error Rate(WER).

Intelligent document processing combines OCR, machine learning, natural language processing, and artificial intelligence to offer more accuracy than OCR. IDP understands concepts and is capable of extracting more information than possible.
How Does OCR Work?
OCR systems or software transform the paper-based document into machine-readable text in the following steps:
Step 1: Image Acquisition
Image acquisition is the first step of OCR document processing, in which a camera or scanner processes the printed or physical document. It scans all the pages of documents and generates a black/white copy of the document.
In these black/white documents, black is for some content like text or numbers, and white is the background.
Step 2: Pre-Processing
After the acquisition of the image, the OCR software applies preprocessing, in which the document is enhanced to get processed. In this step, multiple techniques are applied; some are:
- Deskewing or Titling: This refers to adjusting the alignment of the document during the scan.
- Noise Clearance: Any kind of image spots are removed.
- Script Recognition: The OCR technology, using its compatibility with multiple languages, identifies the script.
- Contrast Adjustments: The Text images are enhanced, and their edges are sharpened.
Step 3: Text Recognition
In this step, the OCR engine typically focuses on one character, word, or block of text at a time. OCR uses two main types of processes.
- Pattern Recognition: The software compares the characters in the document or image with the glyph (stored text image). This typically works when the text in the document and input glyph have similar font and scale.
- Feature Recognition: It uses the features of alphabets, numeric digits, or symbols such as angled lines, crossed lines, and curves to recognize characters. This process works with almost all the modern fonts.
Step 4: Post Processing
After recognizing text, the OCR software represents the wholly processed text and turns it into an end text file that you can use for digital purposes.
However, these OCR results may contain errors. You are required to measure the OCR accuracy level and take steps to improve it.
Why KlearStack Is the Best OCR Engine for Your Business?
If your company is processing 1000s of documents monthly, and want to achieve high OCR accuracy, then look no further!
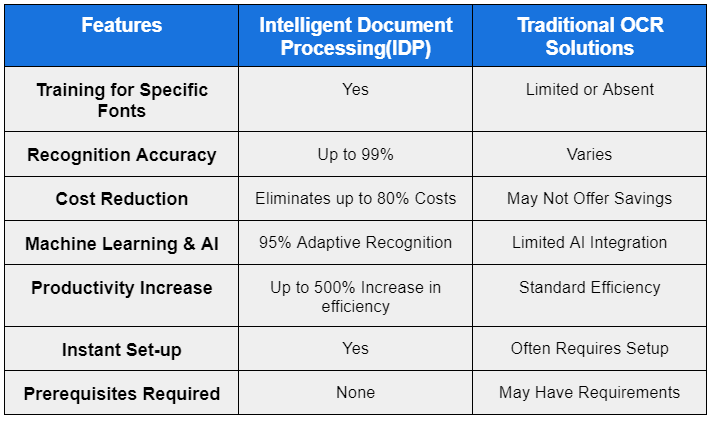
KlearStack is a comprehensive intelligent document processing with an OCR solution. Its high recognition accuracy, cost savings, and advanced AI integration stand out, making it a powerful choice for efficient OCR solutions.
Here’s why KlearStack is the Best OCR Engine for Your Business:
- Allows training for specific fonts or languages,
- 99% recognition accuracy
- Reduces 80% costs
- Leverages Machine Learning and AI
- 500% increase in operational efficiency
- Instant set-up, No pre-requisite required
- Template-less document processing
- Seamless integration with various ERPs and softwares
Take your OCR endeavors to the next level. Schedule a LIVE DEMO CALL and let KlearStack exceed your business expectations today!
FAQs
Good OCR accuracy level varies from 96% to 99%. For business related work, around 98% accuracy is considered safe. Advanced and trained IDP solutions can reach up to accuracy of 99% for their respective trained models.
You should choose the IDP solution which has more than 98% accuracy to minimize errors and enhance reliability.
To assess OCR results, you compare the extracted text to the original source (ground truth). Errors, including substitutions (incorrect characters/words), insertions (extra text), and deletions (missing text), are counted. You can also calculate the OCR results with:
Accuracy (%) = [(Total Characters or Words – Total Errors) / Total Characters or Words] x 100
The F1 score in OCR is a measure of the balance between precision and recall, providing a single metric for overall accuracy. Precision measures the proportion of true positive (correctly recognized) results among all positive results, while recall gauges the proportion of true positives among all actual positives.
Metrics for OCR error assessment include accuracy, precision, recall, and F1 score, which collectively measure how well the OCR system performs in transcribing text from images. Also, there are 2 main metrics to know the OCR accuracy that is Character Error Rate (CER) and Word Errror Rate (WER).

